Download our e-book of Introduction To Python
Related Blog
Matplotlib - Subplot2grid() FunctionDiscuss Microsoft Cognitive ToolkitMatplotlib - Working with ImagesMatplotlib - PyLab moduleMatplotlib - Working With TextMatplotlib - Setting Ticks and Tick LabelsCNTK - Creating First Neural NetworkMatplotlib - MultiplotsMatplotlib - Quiver PlotPython - Chunks and Chinks View More
Top Discussion
How can I write Python code to change a date string from "mm/dd/yy hh: mm" format to "YYYY-MM-DD HH: mm" format? Which sorting technique is used by sort() and sorted() functions of python? How to use Enum in python? Can you please help me with this error? I was just selecting some random columns from the diabetes dataset of sklearn. Decision tree is a classification algo...How can it be applied to load diabetes dataset which has DV continuous Objects in Python are mutable or immutable? How can unclassified data in a dataset be effectively managed when utilizing a decision tree-based classification model in Python? How to leave/exit/deactivate a Python virtualenvironment Join Discussion
Top Courses
Webinars
Most popular Decision Tree Algorithms:-

Sulochana Kamshetty
3 years ago

The journey of Data Scientist, begins understanding with each and every minute thing acquiring knowledge about Different fields like Statistics, Machine Learning, Artificial Intelligence, Text Mining, Natural Language Processing and Lot more things. Let’s understand everything from scrap and cover the most important concept of Decision Tree Algorithm in this content.
On 14 April 1912, despite warnings of ice fields, the ship did not reduce speed and struck an iceberg shortly before midnight. The iceberg ripped a long gash in the side and the ship began to flood. Passengers were unaware and joked about the ice found on the deck. The Captain ordered the lifeboats to be filled and lowered, with women and children first. More than two hours after hitting the iceberg, Titanic sank into the Atlantic Ocean.

Let’s understand what this decision tree, concept helped us giving the detail information about Titanic incident.
Important concepts to cover in this content as follows:-
- Supervised Learning.
- Unsupervised Learning.
- Simple Forecast.
- Choosing the Split.
- Impurity.
- Gini Index.
- Cross Entropy.
- Splitting Based on Numeric Variable.
- Cost complexity pruning.
- Reduced Error Pruning.
- Advantages of Trees.
What is Supervised Learning?
The process of learning a function, for any given training dataset as labelled instances ex:{(x1,y1)….,(XN,YN)}, which maps the given input to an output is defined as supervised learning & in this supervised learning each output is the combination of pairs.
“Goal of the supervised learning”, is to learn a rule(f: x →y) which predicts the output of y for new inputs of x.
The outcome of the provided input, will be always in the form of “Discrete values”, since it’s going to be a classification problem. as shown in the below figure.

What is Unsupervised Learning?
The process of learning a function, for any given training dataset is in the form of unlabeled instances, ex:- {(X1……..Xn)}, which makes to learn about the intrinsic Latent structure which helps to summaries about the data.
The outcome of the Unsupervised Learning provides in two different ways one is in the form of “Clustering ”and other is “Dimensionality Reduction”.
Clustering:- The outcome would be in the form of “Homogenous Group” as latent structure. where the outcome would be clustered into similar data group, as shown in the below figure.
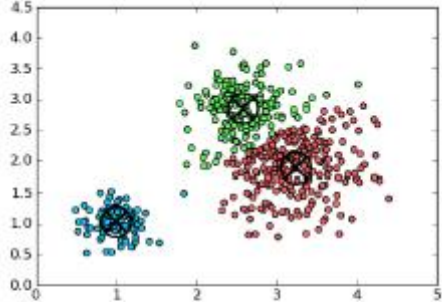
Dimensionality Reduction:- The outcome would be in the form of “low-Dimensional latent structure.”

The best examples suits Unsupervised Learning are:-
- Clustering a large group of images which is simply can be called as “Image database”.
- Top discovery in large collection of text data.
- Also used for many preprocessing steps for supervised learning algorithms{ ex:- To learn/extract good features/to speed up the algorithms, etc.}
Let’s begin understanding the core topic of this content:-
What is Decision Tree?
Decision Tree is widely and are practically used for supervised learning, Via algorithm approach. Which is defined to solve the complex problems into simple solution. which works on the principal of conditions. Decision trees are Non-parametric in nature for supervised learning which is used for both “Regression & classification problems.”
The flow of understanding Decision Tree as follows:-
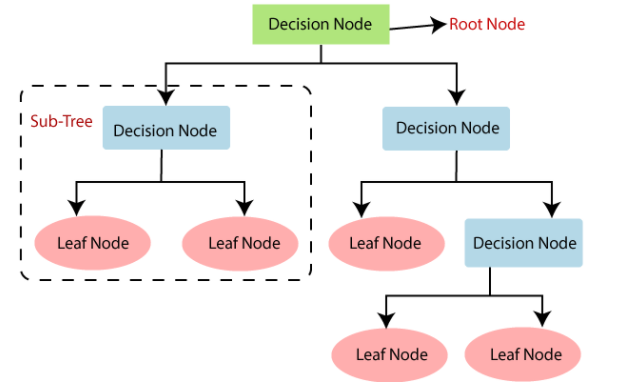
Parts of the Decision Tree:-
- Decision Node — This is also called as “Root Node” which is the start point of splitting the data which represents the whole sample which further divides nodes into sub-nodes.
- Branches — The whole tree is divided and are so called branches, which helps understanding for the next immediate step of division part.
- Splitting — Each node undergoes with splitting part, and further represents information about sub-nodes.
- Terminal Node — The point where splitting stops/ which further don’t provides any information called Terminal node/ also represents the end part of the division of decision tree.
- Pruning — The point where removal of sub-nodes from the decision node is called pruning/or simply called cutting of the unfavorable sub-nodes from the decision node.
- Parent and Child Node — When a node gets divided further then that node is termed as parent node whereas the divided nodes or the sub-nodes are termed as a child node of the parent node.
Concept understanding with the help of Titanic example:-
We have picked important attributes to work with the example in which wanted to predict how many have survived during sinking of ship?
Understanding of the data:-
With the general idea/thought process from titanic data we found the information that 61.6% didn’t survive and 38.4% were survived which clearly indicates that majority didn’t make it…:-(
Now let’s start forecasting using the same info.!!
Step 1:- “Simple forecast”
Lets make that our prediction, A random person in the test set would more likely have died than survived. where our accuracy of prediction is 62% let’s try to make it more better by splitting the data.
Step 2:- Pick the women and men data first according to the movie style, out of which its further divided into “survived and Did not survive” category as shown in the below figure.
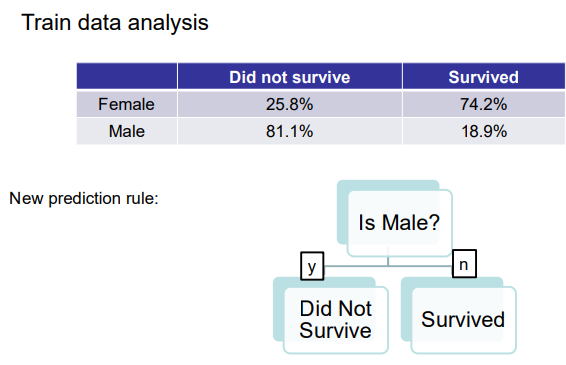
Step 3:- Now the data is further been split into, leaf node that if it is male then whether they are survived or did not survive..
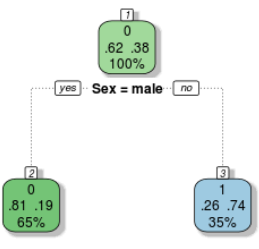
Since the total population of male was 62.38% which is considered as 100% population of male, and when the training data is been pass to the decision tree algorithm using most powerful programming language i.e(“python”)gave the accuracy of 81.19% didn’t survive and 26.74% survived as shown in the above image..!!
Step 4:- Building & Using Trees.
Building in decision tree works with the concept of “IF & THEN Rules” which are specified in the feature space, where the binary split that further feature space into distinct, non-overlapping regions.
Using Trees:- Every observation which is mapped to a leaf node are assigned the label most commonly occurring in that leaf & the final output for the provided data is in the form of “classification method”. If Every observation is mapped to a leaf node also assigned to the mean of the samples in the leaf produces the output in the form of “Regression method”.
Step 5:- Continuous splitting of the feature spaces
Now the feature space includes the total data which gets divided into regions contain “homogeneous” data subsets. where region boundaries define regions. where the root contains all data, & leaves contain “homogeneous” data subsets, also the leaves are defined by the path along the branches..
Theme & Key Variations:-
- Decision Trees : — It Continuous to splitting of the feature space, which is the Recursive Partitioning of the feature space.
- Split : — It Divides the data such that all data in subset-1 is “different” from the data in subset-2 in a certain dimension.
- How to split: — It finds Which variable is used to split the data, also on which value of the variable to split on..!! also checks with what criteria should be used to evaluate a split, what is the split trying to achieve?
- How do you measure the homogeneity of a subset: — In Classification / Regression it works with Supervised learning and gives the output most in the form of Clustering.
{Since that we have understood about splitting the data now let’s cover the most important concept of Decision Tree:-}
What is Good Measure Split?
Decision tree works on Three major components measure of split called:-
- Classification Error:- which deals/ helps to measure the split or it is the measure of set target function, where the target function is also known as classification model, which is mostly used for “Predictive and Descriptive Modelling.”
- Gini Index/Gini Impurity:- Gini Impurity is a measurement of the likelihood of an incorrect classification of a new instance of a random variable, if that new instance were randomly classified according to the distribution of class labels from the data set. if our dataset is Pure then likelihood of incorrect classification is 0. If our sample is mixture of different classes then likelihood of incorrect classification will be high
- Entropy:- It is calculated between 0 & 1depending upon the group or classes, present in the dataset. Which is basically used to measure the purity of the data points. Also quantifies the degree of randomness & reduces the of the uncertainty the target data sets.
Classification error vs. Gini vs. Entropy:-
- It is the measurement of impurity.
- It determines about Information Gain.
- The Determination of split choice is similar for all these measures.
- But for binary classification, all measures reach a maxima at (0.5,0.5) which are symmetrical around the maxima when it reaches the height.
Let’s understand Important Algorithm names:-
- — CART
- — C4.5
- — C5.0
- — CHAID
- — ID3
Two most popular decision tree algorithms:-
- CART :- (Classification & Regression Trees) which was introduced by “Breiman 1984”. A Binary split is used for splitting criteria.
- cart can handle both nominal and numeric attributes to construct a decision tree.
- Implements the concept of Cost complexity pruning, which helps to remove the redundant of branches to improve the performance of the decision tree.
- It smartly handles the missing values for the better outcome of the given datasets.
C5.0:-
The updated version of algorithm C4.5 is C5.0 which was developed by Quinlan (1994) which works with multiple split/multiple branches of tree. takes the advantage to perform on high quality uses Information gain as its splitting criteria. It is pessimistic pruning in nature.
Other Variations where Decision Tree works with:—
- Handling with missing values.
- It can handle more than two child nodes, but one variable appears only once in the entire tree.
- Different category undergoes with surrogate splits etc.
What is a good split Under Classification method?
Among all possible splits (all features, all split points), Which split maximizes gain / minimizes error (Greedy) is considered as good spilt or where it improves the Information Gain /reduces the Impurity reduction also called as good split.
Impact of Decision trees on Regression:-
It turns out that, if we are collecting very similar records at each leaf, we can use median or mean of the records at a leaf as the predictor value,& for all the new records that obey similar conditions. Such trees are called regression trees.
Advantages of Decision Trees:-
- Decision Trees requires very little experimentation.
- They are fast & Robust in nature.
- Can handle both categorical and numerical data.
- Resistant to outliers, hence require little data preprocessing.
Summary of Decision Trees :-
- It is Versatile in nature.
- Can be used for classification, regression & clustering.
- Effectively handle missing values.
- Can be adapted to streaming data.
- The predictive accuracy is not so great. But carries advanced methods exist to fix it.
- Interpretability :-Easy to understand / Easy representation / Easy way to visualize .
- Adapts Human interpretable rules.
- Model Stability :- It carries the High Variance with Strong dependence on training set.
The most popular algorithm of machine learning, is been covered in detailed in this content, but if one is looking for more expertise can acquire knowledge on related topics from.
Like the Blog, then Share it with your friends and colleagues to make this AI community stronger.
To learn more about nuances of Artificial Intelligence, Python Programming, Deep Learning, Data Science and Machine Learning, visit our insideAIML blog page.
Think Creative Be Positive
Happy Learning..