Download our e-book of Introduction To Python
Related Blog
Matplotlib - Subplot2grid() FunctionDiscuss Microsoft Cognitive ToolkitMatplotlib - Working with ImagesMatplotlib - PyLab moduleMatplotlib - Working With TextMatplotlib - Setting Ticks and Tick LabelsCNTK - Creating First Neural NetworkMatplotlib - MultiplotsMatplotlib - Quiver PlotPython - Chunks and Chinks View More
Top Discussion
How can I write Python code to change a date string from "mm/dd/yy hh: mm" format to "YYYY-MM-DD HH: mm" format? Which sorting technique is used by sort() and sorted() functions of python? How to use Enum in python? Can you please help me with this error? I was just selecting some random columns from the diabetes dataset of sklearn. Decision tree is a classification algo...How can it be applied to load diabetes dataset which has DV continuous Objects in Python are mutable or immutable? How can unclassified data in a dataset be effectively managed when utilizing a decision tree-based classification model in Python? How to leave/exit/deactivate a Python virtualenvironment Join Discussion
Top Courses
Webinars
Gradient Descent Algorithm: In-Depth Explanation

Neha Kumawat
3 years ago

Table of Contents
- Introduction
- What is an Optimizer in Machine Learning/Deep Learning?
- Gradient Descent
- What is Cost Function?
- What is Learning rate?
- Types of Gradient Descent Optimizers
1. Batch gradient descent/ Vanilla gradient descent
2. SGD (Stochastic gradient descent)
3. Mini-batch gradient descent
- Momentum
Introduction
In some of my previous articles, I have explained about the
activation functions and loss functions used in machine learning/deep learning.
And also written an article on optimizers and its types. I recommend you to
once go through it for better understanding.
In this article, I will give you an in-depth explanation of
Gradient descent optimizers and its different types.
So, let’s start…
What is an Optimizer in Machine Learning/Deep Learning?
In
previous articles, we saw how to deal with loss functions, which is a
mathematical way of measuring how wrong our predictions are.
During
the training process, we tweak and change the parameters (weights) of our model
to try and minimize that loss function, and make our predictions as correct and
optimized as possible.
But
you may be thinking that how exactly do we do that? How do we change
the parameters of our model, by how much, and when? This all questions are
very important which surely affects our model performance.
Now, where the optimizers come into the
picture. Optimizers try to combine
together the loss function and model parameters by updating the model in
response to the output of the loss function. In simpler terms, we can say that
the optimizers shape and mould our model into its most accurate possible form
by dabbling with the weights. The loss function act as a guide to the
terrain, telling the optimizer when it’s moving in the right or wrong
direction.
Let’s
take a simple example and try to understand what simply happening.
Imagine,
one day you and your friends went for trekking. All of you reached on the top
of a mountain. As you are tired and want some rest, you told your friends to
move forward and get down you will be joining them after taking some rest. While you trying to get down a mountain with
a blindfold on. It’s impossible to know which direction to go in, but there’s
one thing you can know: if you will be going down (making progress) or going up
(losing progress). Eventually, if you keep taking steps that lead you
downwards, you’ll reach the base.
Similarly,
it’s impossible for us to know what our model’s weights should be right from
start. But with some trial and error based on the loss function (whether you descending),
you can end up getting there eventually.

Now as we know any discussion about
optimizers needs to begin with the most popular one, and which is known as Gradient
Descent. This algorithm is used across all types of Machine Learning and
Deep Learning problems which are to be optimized. It’s fast, robust, and
flexible and good performance.
Gradient Descent
Gradient
descent is one of the types of an optimization algorithm used to minimize some
loss function by iteratively moving in the direction of steepest descent as
defined by the negative of the gradient. In machine learning, we use gradient
descent to update the parameters of
our model. These parameters are nothing but they refer to coefficients in Linear
Regression in machine learning
and weights in
neural networks in deep learning.
Let’s see how it works:
1.
It tries to calculate what a small change in
each individual weight would do to the loss function (i.e. which direction
should the hiker walk-in)
2.
Then it adjusts each individual weight-based
on its gradient (i.e. take a small step in the determined direction)
3.
It keeps iterating step 1 and step 2 until the
loss function gets as low as possible and get the best model.
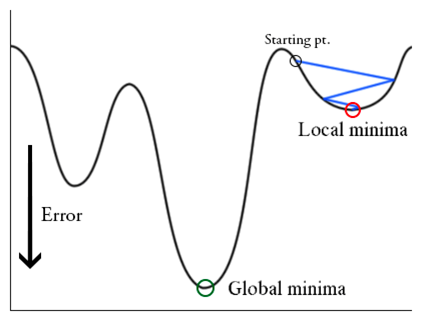
Note: The ultimate aim of this algorithm is to
reach to the global minima and do not get stuck at the local minima.
So, you might be thinking about what is Gradient and
descent is in gradient descent algorithm?
As of now, you may know, Gradients are nothing but partial
derivatives wrt weights and loss and are a measure of change. And Descent means
in which direction we should move to achieve global minima. They connect
the loss function and the weights; they tell us what specific operation we
should perform to our weights – add 6, subtract .06, or anything else which
helps us to lower the output of the loss function and thereby make our model
more accurate.
There are some other elements such as cost function, learning
rate, etc. which play an important role that makeup Gradient Descent and also
generalize to other optimizers.
What is Cost Function?
The main point for learning neural networks is to define a
cost function which is also known as a loss function. Cost/Loss functions measures
how well the network predicts outputs on the test set. The goal is to then find
a set of weights and biases values that minimizes the cost/loss. One common
function that is often used is the mean squared error, which measures the difference between the actual value
of y and
the estimated value of y (the prediction).
The equation of the below regression line is hθ(x)
= θ + θ1x,
which has only two parameters: weight (θ1) and bias (θ0).

What is Learning Rate?
Learning rate is nothing but the size
of the steps. It plays a very important role in optimizing
our model. With a high value of learning rate, we can capture more ground in
each step, but we may risk overshooting the minima point as the slope of the
hill is constantly changing. On the other hand, with a very low learning rate,
we can move in the direction of the negative gradient as we are recalculating
it so frequently.
A low learning rate is more precise, but it’s a
time-consuming, so it will take us a very long time to achieve the global
minima point. (lowest point) and sometimes it also gets stuck at the local
minima.
So, choosing the correct value of the learning rate plays
an important role in our model performance.
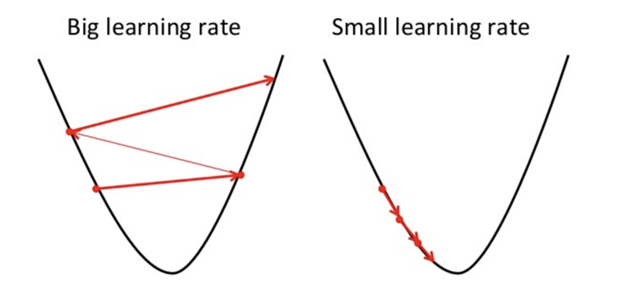
Let’s
take an example and try to understand how the gradient descent works?
Let’s
try to predict the price of a new how house from the given housing data:
Below
is the given historical data:

Task: In
this example our task is to predict the price of a new house based on the size
of the house.
Let’s plot the given historical
housing data:
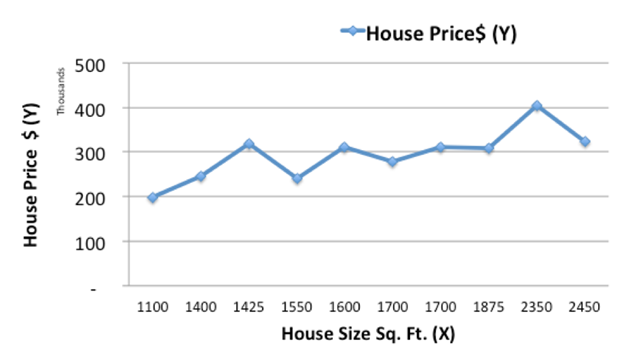
From the above figure, we can see it follows a linear trend
as the size of the house increases, the price is also increasing.
Next, let’s try to use a simple linear regression model,
where we try to fit a line on the given historical data and predict the price
of a new house (Ypred) based on its size (X).
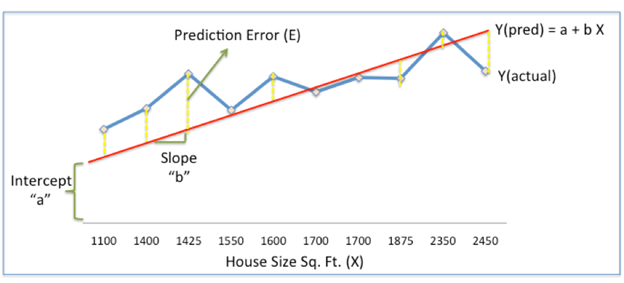
From
the above figure, we can see that the red line gives the predicted house price
(i.e., Ypred) given house size(X).
So,
Ypred can be given as:
Ypred = a+bX
Now, the blue line represents the actual prices from the
historical data i.e., Yactual.
The difference between Yactual and Ypred which is represented
by the yellow dashed lines is called prediction error (error) E.
So now, our aim is to find a line with optimal values of a, b
which is known as coefficients/weights that best fits the historical data by
reducing the prediction error/ error and improving prediction accuracy.
Here, our goal is to find optimal values of a, b that
can minimizes the error between actual and predicted values of house price
(NOTE: 1/2 is used for mathematical convenience since it helps us
in calculating gradients in calculus easily)
Sum of Squared Errors (SSE) = ½
Sum (Actual House Price – Predicted House Price)2
SSE = ½ Sum (Y – Ypred)2
Note: There are other types of measures of Error. Here, we used SSE
which is just one of them).
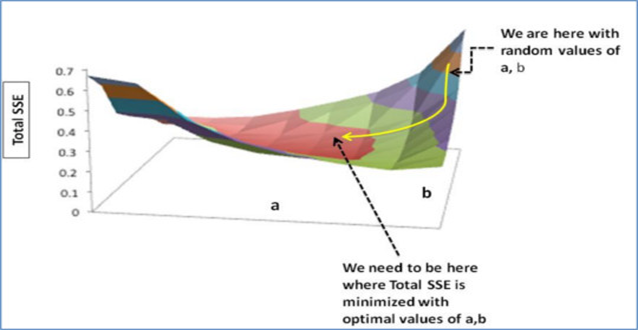
This
is where the Gradient Descent comes into the picture. Gradient descent is an
optimization algorithm that finds the optimal values of weights a, b that reduces
the prediction error.
Let’s now try to understand the Gradient Descent algorithm
with an example:
Below are the steps involved in the gradient descent algorithm
are mentioned.
Step 1: First,
Initialize the weights (a & b) with random values and calculate Error (SSE).
Step 2: Calculate
the gradient, i.e. change in SSE when the weights (a & b) are changed by a
very small value from their original randomly initialized value. This helps us
move the values of a & b in the direction in which SSE can be minimized.
Step 3: Now,
we adjust the weights with the gradients to reach the optimal values so that SSE
can be minimized.
Step 4: Use
these new weights for prediction and then calculate the new SSE.
Step 5: Finally,
we repeat steps 2 and 3 till further adjustments to weights doesn’t
significantly reduce the Error.
Let’s
now go through each of the steps in detail.
But
before that, we have to standardize the data as it will make the optimization
process faster and convenient.
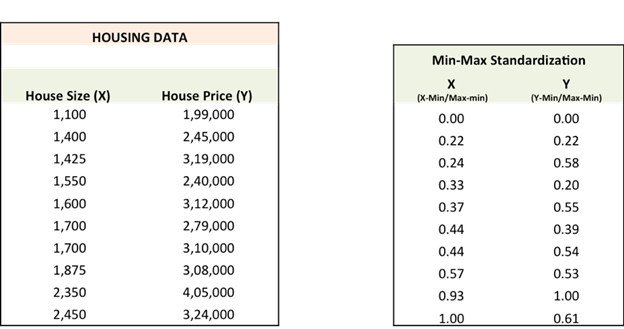
Step 1: To fit a line Ypred = a + b X, we start
off with random values of a and b and then calculate the prediction error (SSE)
accordingly as shown below.
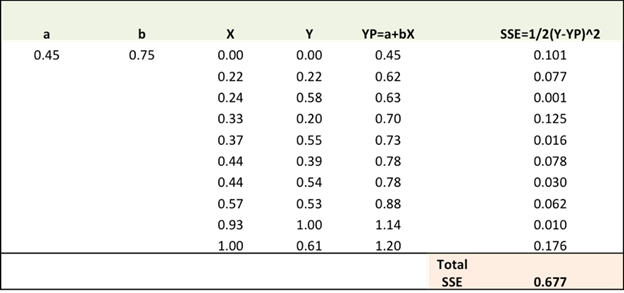
Step 2: In our second
step we calculate the error gradient w.r.t
the weights as shown below.
∂SSE/∂a
= – (Y-Ypred)
∂SSE/∂b
= – (Y-Ypred) X
Here, SSE = ½ (Y-Ypred)2 = ½ (Y- (a+bX))2
Here, ∂SSE/∂a and ∂SSE/∂b are the gradients and
which give the direction of the movement of a, b w.r.t to SSE.
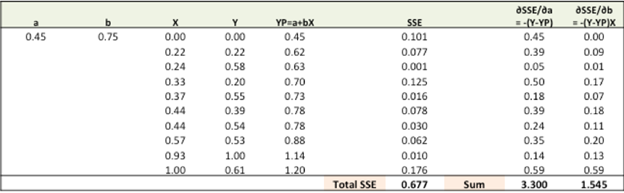
Step 3: Adjust the weights with the gradients to reach
the optimal values where SSE is minimum.
Now, we need to
update the random values of a, b so that we can move in the direction of
optimal a, b where total SEE is minimum.
Update
rules:
·
a – ∂SSE/∂a
·
b – ∂SSE/∂b
So, update rules:
1.
New a = a – lr * ∂SSE/∂a = 0.45-0.01*3.300
= 0.42
2.
New b = b – lr * ∂SSE/∂b= 0.75-0.01*1.545
= 0.73
Here, lr is the
learning rate = 0.01, which is the pace of adjustment to the weights. I already
explained you about learning rate earlier.
Note: These
values are randomly taken to explain you the concepts. Don’t consider them as a
fixed one.
Step 4: Now, we use these new a and b values for our prediction and
then use it to calculate the new Total SSE.
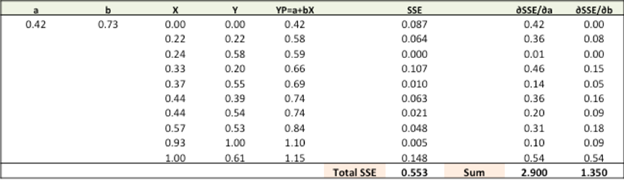
Now we can observe
from the above table, with the new prediction, the total SSE has gone down
(0.677 to 0.553). That implies our prediction accuracy has improved and model
will show better performance.
Step 5: Finally, in our last step we repeat
step 3 and 4 till the time further adjustments to a, b doesn’t show significantly
reduce the error.
At
that time, we have arrived at the optimal value of a, b with the highest
prediction accuracy.
This is how the
Gradient Descent Algorithm works behind the scene. This optimization algorithm
and different variants form the core of many machine learning and Deep
Learning.
Note: We don’t
have to do all this manually. There are many built-in functions available which
performs all this for us. Only we have to call them.
Types of Gradient Descent Optimizers
There
are many different types but mainly these three variants of gradient descent
are common, which differ in how much data we use to compute the gradient of the
objective function. Depending on the amount of data, we make a trade-off
between the accuracy of the parameter update and the time, it takes to perform
an update.
1.
Batch
gradient descent/ Vanilla gradient descent
2.
SGD
(Stochastic gradient descent)
3.
Mini-batch
gradient descent
Let’s
see how they differ from each other’s.
1. Batch gradient descent/ Vanilla gradient descent
Gradient
update rule: BGD uses the data of the entire training set to calculate
the gradient of the cost function to the parameters:
Disadvantages:
Because
this method calculates the gradient for the entire data set in one
update, the calculation is very slow, it will be very tricky to encounter a large number of data sets, and you cannot invest in new data to update the
model in real-time.
We
will define an iteration number epoch in advance, first calculate the gradient
vector params_grad, and then update the parameter params along the direction of
the gradient. The learning rate determines how big we take each step.
Batch
gradient descent can converge to a global minimum for convex functions and to a
local minimum for non-convex functions.
2. SGD (Stochastic gradient descent)
Gradient
update rule: Compared with BGD's
calculation of gradients with all data at one time, SGD updates the gradient of
each sample with each update.
x += -
learning_rate * dx
where x is a
parameter, dx is the gradient and learning rate is constant
For large
data sets, there may be similar samples, so BGD calculates the gradient. There will be
redundancy, and SGD is updated only once, there is no redundancy, it is faster,
and new samples can be added.
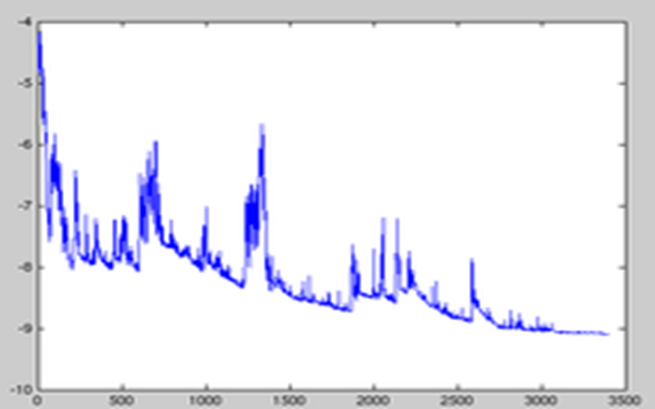
Disadvantages: However, because SGD is updated more frequently, the cost
function will have severe oscillations. BGD can converge to a local minimum, of
course, the oscillation of SGD may jump to a better local minimum.
When we
decrease the learning rate slightly, the convergence of SGD and BGD is the
same.
3. Mini-batch gradient descent
Gradient update rule:
MBGD uses a
small batch of samples, that is n samples to calculate each time. In this way,
it can reduce the variance when the parameters are updated, and the convergence
is more stable. It can make full use of the highly optimized matrix operations
in the deep learning library for more efficient gradient calculations.
The
difference from SGD is that each cycle does not act on each sample, but a batch
with n samples.
Setting value of hyper-parameters: n Generally value is 50 ~ 256
Cons:
- Mini-batch gradient descent does not guarantee good convergence,
- If the learning rate is too small, the convergence rate will be slow. If it is too large, the loss function will oscillate or even deviate at the minimum value. One measure is to set a larger learning rate. When the change between two iterations is lower than a certain threshold, the learning rate is reduced.
However,
the setting of this threshold needs to be written in advance adapt to the
characteristics of the data set.
In
addition, this method is to apply the same learning rate to all parameter updates. If our data is sparse, we would
prefer to update the features with lower frequency.
In
addition, for non-convex functions, it is also necessary to avoid trapping at the local
minimum or saddle point, because the error around the saddle point is the same,
the gradients of all dimensions are close to 0, and SGD is easily trapped here.
Saddle points are
the curves, surfaces, or hypersurfaces of a saddle point neighborhood of a
smooth function are located on different sides of a tangent to this point. For
example, this two-dimensional figure looks like a saddle: it curves up in the
x-axis direction and down in the y-axis direction, and the saddle point is (0,0).
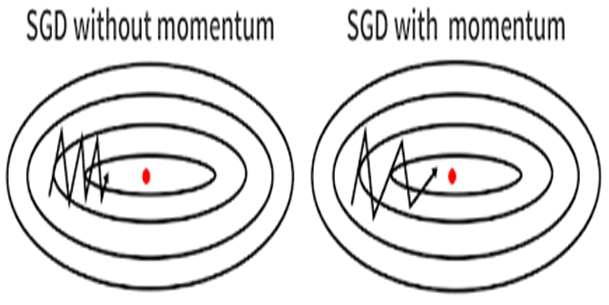
Momentum
One
disadvantage of the SGD method is that its update direction depends entirely on
the current batch, so its update is very unstable. A simple way to solve this
problem is to introduce momentum.
Momentum is momentum, which simulates the inertia of an object when it is moving, that
is, the direction of the previous update is retained to a certain extent during
the update, while the current update gradient is used to fine-tune the final
update direction. In this way, you can increase the stability to a certain
extent, so that you can learn faster, and also have the ability to get rid of
local optimization.
I hope after reading this article, finally, you came to know what is Gradient descent optimizers, how its work, different types, and
its importance. In the next articles, I will come with a detailed explanation
of some other types of optimizers. For more blogs/courses on data
science, machine learning, artificial intelligence, and new technologies do
visit us at InsideAIML.
Thanks for reading…