Download our e-book of Introduction To Python
Related Blog
Matplotlib - Subplot2grid() FunctionDiscuss Microsoft Cognitive ToolkitMatplotlib - Working with ImagesMatplotlib - PyLab moduleMatplotlib - Working With TextMatplotlib - Setting Ticks and Tick LabelsCNTK - Creating First Neural NetworkMatplotlib - MultiplotsMatplotlib - Quiver PlotPython - Chunks and Chinks View More
Top Discussion
How can I write Python code to change a date string from "mm/dd/yy hh: mm" format to "YYYY-MM-DD HH: mm" format? Which sorting technique is used by sort() and sorted() functions of python? How to use Enum in python? Can you please help me with this error? I was just selecting some random columns from the diabetes dataset of sklearn. Decision tree is a classification algo...How can it be applied to load diabetes dataset which has DV continuous Objects in Python are mutable or immutable? How can unclassified data in a dataset be effectively managed when utilizing a decision tree-based classification model in Python? How to leave/exit/deactivate a Python virtualenvironment Join Discussion
Top Courses
Webinars
FastText: A Word Embedding Technique

Kajal Pawar
3 years ago

Table of Contents
- Introduction
- What is fastText?
- The Intuition behind FastText using visualization
- Implementation of FastText word embedding using genism package in python
- FastText implementation using genism
Introduction
In some of my previous articles, I have explained different types of word embedding and their implementation using python. I recommend you have a look at it first and then come back to this article for better understanding. Below are the links of my previous articles:
Word Embedding using Python Gensim package
Word embedding Word2vec by google
If you have already gone through my previous articles, then I think that you may already understand some of the most important concepts used in Natural Language Processing (NLP) such as word embedding and some types and importance of them. So, in this article, I will try to take you through one of the new and advanced topics: fastText.
One my close friends booked a new car. So, he put his status update on Facebook
about purchasing a car. To share his joy with, I made a comment and also shared
his post with others. Suddenly, a few hours later I saw Facebook serves me a
car ad on my screen. I was surprised to saw… Don’t you? As I was not posted
that post. This is not black magic! This
is Facebook leveraging text data to serve you better ads and provide you with better
services.
In the below picture is shown how
it faced a challenge while dealing with text data.

From the above picture, you may observe how it clearly failed to deliver the right ad. It is all the more important to capture in which the word has been used. This is a common problem in Natural Language Processing (NLP) tasks.
The same word can be used with the same spelling and pronunciation in multiple contexts. So, to overcome this problem, a potential solution is devolved which is computing word representations.
Now, you may imagine how Facebook manage this challenge. Facebook deals with an enormous of text data on a daily basis in different form such as status updates, comments etc. And it is all the more important for Facebook to utilize this text data to serve its users in a better way. And using this text data generated
by billions of users on a daily basis, to compute word representations was a very time expensive task until. So, Facebook developed its own library known as FastText, for Word Representations and Text Classification.
What is fastText?
FastText is an
open-source library created by the Facebook research team for learning word
representations and sentence/text classification. It works on standard and generic
hardware.
In
the NLP community, it is quite popular as it’s a possible substitution to
the gensim package which provides the functionality of Word Vectors etc. for
different models such as Word2Vec.
In
simple words, we can say that FastText is another word embedding technique that
is an extension of the word2vec model. In FastText model, it represents each
word as an n-gram of characters instead of learning word vector directly.
For
example, take the word, “eating” and let n = 3 (here, n represent the number of
grams).
The
FastText represent this word as < ea, eat, ati, tin, ing, ng >,
where angular bracket represents the starting and ending of the word.
I
know as of now you may be little confused but let me take the above example and
explain to you using visualization.
The Intuition behind FastText using visualization
To solve the disadvantages of Word2Vec model, FastText model uses
the sub-structure of a word to improve vector representations obtained from the
skip-gram method of Word2Vec.
Generation of Sub-word
For
a given word, we generate character n-grams.
STEP 1: We take a word and add angular brackets around it which represents the
beginning and end of a word as shown in the below figure.

STEP 2: We generate character n-grams of length n. For example, for the word “eating”, character n-grams of length 3 can be generated by sliding a window of 3 characters from the start of the angular bracket till the ending angular bracket is reached. In the below image you may observe how we shift the window one step each time by green color.

STEP 3: We will get a list of character n-grams for a word as shown below.

Let’s
see some examples of different length character n-grams.
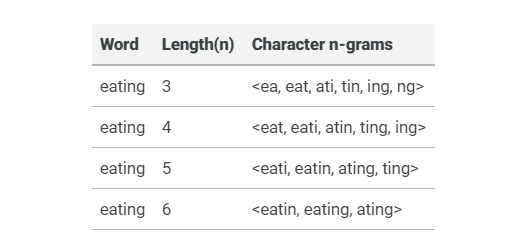
From
the above table, we can see how we can create a different length of n-grams of
taken example word “eating”.
Since
there can be a huge number of unique n-grams may present in the dataset, we
apply hashing technique to bound the memory requirements.
In
the hashing technique, we instead of learning an embedding for each unique
n-gram, we learn total B embeddings where B represents the bucket size. In the
original paper, they used a bucket size of 2 million.
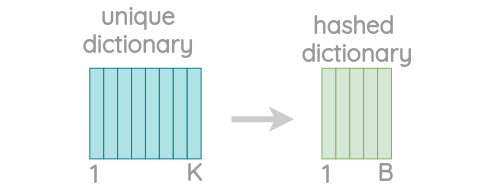
From the above figure, we can observe that each character n-gram is hashed to an integer between 1 to B. This helps us to control the vocabulary size but may result in collisions. In the original paper, they used the FNV-1a variant of the Fowler-Noll-Vo hashing function to hash character sequences to integer values.

Skip-gram with negative sampling
To understand the Skip-gram with negative sampling, let’s take a simple example.
Let’s suppose, we have a sentence “I am eating food now” and at the center, we have the word “eating” and we want to predict the neighbor's (context) words “am” and “food”.

Steps involved:
1) Firstly, we calculate the embedding vector for the center word, then take a sum of vectors for the character n-grams and the whole word itself as shown in the figure below.

2) Secondly, we directly take word vector of the actual context words from the embedding table, without adding the n-grams character as shown below:

3) Then, we collect negative samples randomly with probability equals to the square root of the unigram frequency.
Note: For one actual context word, we take 5 negative random sample words.

4) Now in our next step, we take the dot product of the centre word and the actual context words and then apply a sigmoid function on it to get value in between 0 and 1.
5) Finally, according to the loss obtained, we try to update the embedding vectors with Stochastic gradient descent (SGD) optimizer which helps us to bring actual context words closer to the centre word and increase the distance to the negative samples. It is shown in the image below.

Implementation of FastText word embedding using genism package in python
Here, I will show you how we can perform word embedding with Gensim, package of python for NLP.
For this example, I will use a TED Talk dataset. You can download the dataset from the below given link:
https://wit3.fbk.eu/get.php?path=XML_releases/xml/ted_en-20160408.zip&filename=ted_en-20160408.zip
Or
we can directly write python code and download the dataset using urllib, extracted the subtitle from the file. It can be done as shown below:
#import required libraries
import numpy as np
import os
from random import shuffle
import re
import urllib.request
import zipfile
import lxml.etree
#download the data
urllib.request.urlretrieve("https://wit3.fbk.eu/get.php?path=XML_releases/xml/ted_en-20160408.zip&filename=ted_en-20160408.zip", filename="ted_en-20160408.zip")
# extract subtitle
with zipfile.ZipFile('ted_en-20160408.zip', 'r') as z:
doc = lxml.etree.parse(z.open('ted_en-20160408.xml', 'r'))
input_data = '\n'.join(doc.xpath('//content/text()'))
Let’s print some part of the dataset and take a look at what
input_data variable stores.
The output is shown below in the image:
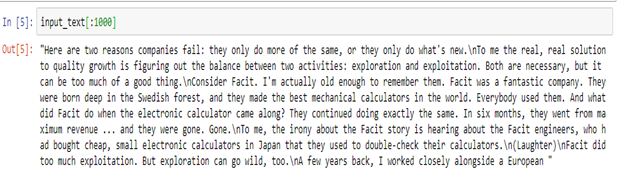
From the above image, we may clearly observe that there are some irrelevant information present in the dataset that are not helpful for us to understand the meaning, such as the words describing sound in the parenthesis and the speaker’s name. We can get rid of these words with the help of python regular expressions.
# remove parenthesis
input_text_noparens = re.sub(r'\([^)]*\)', '', input_data)
# store as list of sentences
sentences_strings_ted = []
for line in input_text_noparens.split('\n'):
m = re.match(r'^(?:(?P[^:]{,20}):)?(?P.*)$', line)
sentences_strings_ted.extend(sent for sent in m.groupdict()['postcolon'].split('.') if sent)
# store as list of lists of words
clean_sentences_ted = []
for sent_str in sentences_strings_ted:
tokens = re.sub(r"[^a-z0-9]+", " ", sent_str.lower()).split()
clean_sentences_ted.append(tokens)
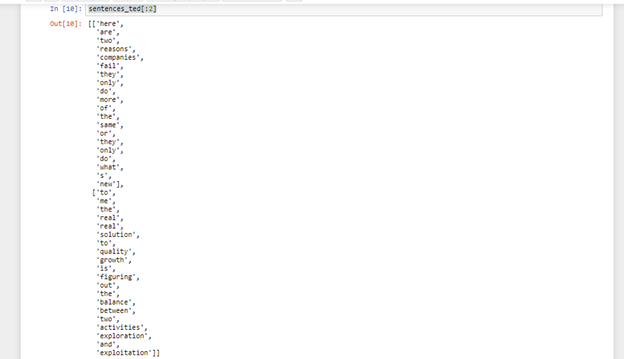
Now, clean_sentences_ted has been transformed into a two-dimensional array with each element being a word. Let’s print out the first and the second element.
print(clean_sentences_ted[:2])
Following image shows the above code output:
FastText implementation using genism
It’s pretty simple to implement FastText using gensim package. we only need one line to specify the model that trains the word embedding on FastText.
It can be done as follows:
from gensim.models import FastText
fast_model = FastText(sentences_ted, size=100, window=5, min_count=5, workers=4,sg=1)
Let’s try it to predict with the word “Gastroenteritis”, which is rarely used and does not appear in the training dataset.
fast_model.wv.most_similar("Gastroenteritis")
Output
[('arthritis', 0.7805954217910767),
('h1n1', 0.7803696990013123),
('cdc', 0.7635983228683472),
('amygdala', 0.7610822319984436),
('penitentiary', 0.7592360973358154),
('tuscaloosa', 0.7576302289962769),
('inflammatory', 0.7538164854049683),
('amyloid', 0.7519340515136719),
('cesarean', 0.7514520883560181),
('aromatase', 0.7490667104721069)]
We can see from the above output, even though the word “Gastroenteritis” does not exist in the training dataset but it is still capable of figuring out this word is
closely related to some medical terms.
If we try this in the Word2Vec model, it would produce an error because such
the word does not exist in the training dataset. Although it takes a longer time to train a FastText model as it considers the number of n-grams is greater than the number of words, it performs better than Word2Vec and allows rare words to be
represented appropriately.
I recommend you to go through this official website for the model, and try to understand it.
https://github.com/facebookresearch/fastText
If you also want to have a look at the word2vec model, you may also read my article” Word embedding - Word2vec by google” and Word Embedding using Python Gensim package.
After reading this article, finally, you came to know the importance of the FastText model and its benefits.
For more blogs/courses on data science, machine learning, artificial intelligence, and new technologies do visit us at InsideAIML.
Thanks for reading…