Download our e-book of Introduction To Python
Related Blog
Matplotlib - Subplot2grid() FunctionDiscuss Microsoft Cognitive ToolkitMatplotlib - Working with ImagesMatplotlib - PyLab moduleMatplotlib - Working With TextMatplotlib - Setting Ticks and Tick LabelsCNTK - Creating First Neural NetworkMatplotlib - MultiplotsMatplotlib - Quiver PlotPython - Chunks and Chinks View More
Top Discussion
How can I write Python code to change a date string from "mm/dd/yy hh: mm" format to "YYYY-MM-DD HH: mm" format? Which sorting technique is used by sort() and sorted() functions of python? How to use Enum in python? Can you please help me with this error? I was just selecting some random columns from the diabetes dataset of sklearn. Decision tree is a classification algo...How can it be applied to load diabetes dataset which has DV continuous Objects in Python are mutable or immutable? How can unclassified data in a dataset be effectively managed when utilizing a decision tree-based classification model in Python? How to leave/exit/deactivate a Python virtualenvironment Join Discussion
Top Courses
Webinars
NLP - Word Tokenization with Python

Shashank Shanu
2 years ago

Table of Content
- What is NLP?
- What is NLTK?
- How we can do Tokenization in python
- Tokenizing Sentences
- Why Tokenization is so important?
What is NLP?
Natural Language Processing, or NLP for short,
is a process of converting human languages into something which a machine can
understand so that we can process it and get some useful outputs.
Here I will try to take you through one of the processes used by the NLTK package to perform NLP.
Now, what is NLTK?
Natural Language The toolkit is a framework used for natural language processing works.
NLTK is a leading platform for building Python
programs to work with human language data. It provides easy-to-use interfaces
to over 50 corpora and lexical resources such as WordNet, along with a suite of text
processing libraries for classification, tokenization, stemming, tagging,
parsing, and semantic reasoning, wrappers for industrial-strength NLP libraries.
Here
I will take you through the word tokenization technique.
Word tokenization is
the process of splitting a large sample of text into words. This is a
requirement in natural language processing tasks where each word needs to be
captured and subjected to further analysis like classifying and counting them
for a particular sentiment etc. The Natural Language Tool kit (NLTK) is a
library used to achieve this. Install NLTK before proceeding with the python
program for word tokenization.
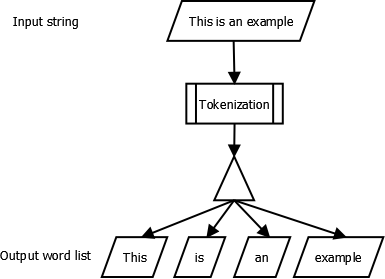
Lets we how we can do it in python
We
can install nltk as
conda install -c anaconda nltk
Next, we use the word
tokenization method to split the paragraph into individual words.
Let’s see it with an
example
import nltk
word_data = "It originated from the idea that there are readers who prefer learning new skills from the comforts of their drawing rooms"
nltk_tokens = nltk.word_tokenize(word_data)
print (nltk_tokens)
When we execute the
above code, it produces the following result.
['It', 'originated', 'from', 'the', 'idea', 'that', 'there', 'are', 'readers',
'who', 'prefer', 'learning', 'new', 'skills', 'from', 'the',
'comforts', 'of', 'their', 'drawing', 'rooms']
Tokenizing Sentences
We can also tokenize
the sentences in a paragraph like we tokenized the words. We use the method sent
tokenize to achieve this. Below is an example.
import nltk
sentence_data = "Sun rises in the east. Sun sets in the west."
nltk_tokens = nltk.sent_tokenize(sentence_data)
print (nltk_tokens)
When we execute the
above code, it produces the following result.
['Sun rises in the east.', 'Sun sets in the west.']Why Tokenization is so important?
Tokenization is the first step to proceed with
NLP. And, it is important because by this, words are identified, demarcated and
classified.
This not only permits to further
steps in processing but this allows the computer to deal with words in a much
manageable form (internally each word is represented by code and, remember,
the computer is a number oriented device).
I hope you enjoyed reading this article and finally, you came
to know about NLP - Word Tokenization with Python.
For more such blogs/courses on data science, machine
learning, artificial intelligence and emerging new technologies do visit us at InsideAIML.
Thanks for reading…
Happy Learning…